漢書・後漢書に見る遼東郡・楽浪郡・玄菟郡
邪馬台国の位置を確定するためには、起点の帯方郡の位置を確定する必要があるが、魏誌巻30烏丸鮮卑東夷倭人伝では情報不足の感があるため漢書・後漢書を調べることにする。
当然だが、地誌の類となると完全に嘘を書き並べる理由は存在しない。何故なら、これらの書物は日本で言う勅撰であり、嘘を書き並べた場合、皇帝の顔に泥どころか糞尿を塗りたくる行為になりかねないからである。何度でも言うが、各史書に共通するのは皇帝の面子を潰さない限り事実を書くことになる。そうしないと史書の様を為さないという実用的な理由も存在するからである。
原文はhttp://hanchi.ihp.sinica.edu.tw/から引用した。暁美焔(Xiao Meiyan)氏に感謝する。
地理志第八下 遼東郡
縣八:襄平,有牧師官。莽曰昌平。新昌,無慮,西部都尉治。望平,大遼水出塞外,南至安市入海,行千二百五十里。莽曰長說。房,候城,中部都尉治。遼隊,莽曰順睦。遼陽,大梁水西南至遼陽入遼。莽曰遼陰。險瀆,[四]應劭曰:「朝鮮王滿都也。依水險,故曰險瀆。」臣瓚曰:「王險城在樂浪郡浿水之東,此自是險瀆也。」師古曰:「瓚說是也。浿音普大反。」居就,室偽山,室偽水所出,北至襄平入梁也。高顯,安市,武次,東部都尉治。莽曰桓次。平郭,有鐵官、鹽官。西安平,莽曰北安平。文,莽曰(受)〔文〕亭。番汗,沛水出塞外,西南入海。沓氏。
遼東郡險瀆には嫌われ者の衛満の都がおいてあったとある。王險城は楽浪郡に存在し浿水の東にあったともある。つまり、楽浪郡は遼東郡に近接していたことになる。余談だが西安平は王莽の時代に北安平としていたことが分かった(莽曰北安平)。なお、筑摩書房版の和訳本では単に「莽に」としか書いてないので意味不明だった。ここの中国史書は貴重な和訳本なのだが、こういう意味不明な訳を載せるのが困りものである。因みに莽の意味を調べると広場とか草叢とかそんなものが出てくる。翻訳者は疑問に思わなかったのだろうか。
この筑摩翻訳版の漢書地理志下にはこの情報がなく、險瀆については「王險城は楽浪郡浿水の東」とある。また沛水についての脚注では勝手に鴨緑江に平行する川と書いているが、地図を見る限りそんなものは存在しない。というのはこのような地誌に書かれる川は基本大河であり、幅10mもない小川について書いてある筈もない。そんなものまで書いたら最後、地誌の量が際限なく増える事になる。訳者の小竹が地図も確認しなかったことは確実だろう。
衛満は衛氏朝鮮の創立者だが、箕氏朝鮮王準を追い出して国を乗っ取ったので、中国皇帝から嫌われていた節がある。 隋の煬帝は高句麗遠征の理由として箕氏朝鮮の故地を取り戻すとあった。衛氏朝鮮ではない。日本だと箕氏朝鮮は伝説上の存在という事になっているが、この箕氏というのは殷王朝最後の王、紂王の叔父に当たる人物で周の武王が殷を滅ぼした時に、余りにも素晴らしい聖人だったので、朝鮮王に封じた。この朝鮮国を箕氏朝鮮という。つまり、周の武王が箕氏に立てさせた由緒正しい国だったわけである。
尚、契丹古伝という書物にもこの衛満は登場しているのだが、名前が衛瞞となっていた。瞞には欺くとか騙すという意味がある。この文書(と言っても他からの引用とあるが)の著者がどれ程、衛瞞を怨んでいたか良く解る。
地理志第八下 玄菟郡
玄菟郡,武帝元封四年開。高句驪,莽曰下句驪。屬幽州。戶四萬五千六,口二十二萬一千八百四十五。縣三:高句驪,遼山,遼水所出,西南至遼隊入大遼水。又有南蘇水,西北經塞外。上殷台,莽曰下殷。西蓋馬。馬訾水西北入鹽難水,西南至西安平入海,過郡二,行二千一
この記事を読むと遼水は大遼水に合流するらしい。また蘇水という川があり、高句麗の北西の領域外を流れているらしい。上殷台の位置は不明だが、殷の文字を使っていることに何か因縁を感じるのは私だけだろうか。また西蓋馬で流れる川は西安平で海に入るとある。その西安平は遼東にあるので玄菟郡はその近くである。
最後に楽浪郡を示す。
地理志第八下 樂浪郡
樂浪郡,武帝元封三年開。莽曰樂鮮。屬幽州。戶六萬二千八百一十二,口四十萬六千七百四十八。有雲鄣。縣二十五:朝鮮,䛁邯,浿水,水西至增地入海。莽曰樂鮮亭。含資,帶水西至帶方入海。黏蟬,遂成,增地,莽曰增土。帶方,駟望,海冥,莽曰海桓。列口,長岑,屯有,昭明,南部都尉治。鏤方,提奚,渾彌,吞列,分黎山,列水所出,西至黏蟬入海,行八百二十里。東暆,不而,東(郡)〔部〕都尉治。蠶台,華麗,邪頭昧,前莫,夫租。
浿水は増地で西に流れてから海に入るとある。また帯水も浿水同様帯方で海に入るとある。吞列という所は県内の分黎山で列水が出るところで,西に流れて黏蟬で海に入る。
楽浪郡には朝鮮県と帯方県が含まれる。今の朝鮮半島にある国家程の広さを持っていなかったことは明白である。定説通りなら、朝鮮県はもっと広大な土地を占有しただろう。
次に後漢書で遼東郡や楽浪郡について書かれた部分を抜粋する。少なくとも読み下し文を提示するのがいいだろうが、そこまでの能力がないので、関係する文を全部抜粋という暴挙に走った。
楽浪郡の位置を明記している部分を抜粋する。
初,樂浪人王調據郡不服。([一]樂浪,郡,故朝鮮國也,在遼東。)秋,遣樂浪太守王遵擊之,郡吏殺調降。
ここで楽浪郡が元は朝鮮国(衛氏朝鮮)であり、遼東にあったとある。実際漢の時に衛氏朝鮮を滅ぼして漢四郡と呼ばれる行政区域に分割した。楽浪郡はそのうちの一つである。
志第二十三 郡國五 幽州 遼東郡
襄平・新昌・無慮・望平・候城・安巿・平郭有鐵。
西安平は後に高句麗の来寇を受けるが、北に小水が流れ、南に流れて海に入る。そして高句麗の別種が住み、小水箔の名の由来になったとある。ここも遼東郡にある。汶県と番汗県が並べられているのは隣り合うからだと思われる。
志第二十三 郡國五 幽州 玄菟郡
高句驪遼山,遼水出。([一]山海經曰:「遼水出白平東。」郭璞曰:「出塞外(銜)〔衞〕白平山。遼山,小遼水所出。」)西蓋(鳥)[馬]・上殷台・高顯故屬遼東。
候城故屬遼東。遼陽故屬遼東。
最初は高句麗は遼山にあり、遼水が出るの意味だろうが、この川の名前は山海経に拠ると小遼水とある。西蓋馬は名前から判断するに恐らく蓋馬大山の西にあるらしい。上殷台の位置は不明だが、この後の3県も遼東に属していたとある。
玄菟郡はあちこち移動しているという説があるが、そんなアホなことはあり得ないので、配下の県についての変遷はあっても基本的な位置は変わらないものと考えるべきである。
次は楽浪郡である。
志第二十三 郡國五 幽州 樂浪郡
朝鮮・𧦦邯・浿水・含資・占蟬・遂城・增地・帶方・駟望・海冥・列口([一]郭璞注山海經曰:「列,水名。列水在遼東。」)・長岑・屯有・昭明・鏤方・提奚・渾彌・樂都
県の数が漢書の25から18に減っているため、漢書と名前が合わないものがある。恐らく県を整理して数を減らしたものと思われるが、漢書の「吞列,東暆,不而,蠶台,華麗,邪頭昧,前莫,夫租」の各県が消え、後漢書では「鏤方・樂都」の2県が登場する。
漢書では列水は楽浪郡呑列県から出ているとあったが、後漢書ではその情報が消えている。その代わり列水は遼東にある。この情報は重要で、定説にある北朝鮮のどこぞの川でないことは明白である。
結論など漢書地誌を読むだけで出てくるが、結局後の帯方郡を含む楽浪郡は相当広大な土地に見え、その位置は遼東である。浿水や列水、帯水が遼東のどこかにあることも確実である。恐らく現在の遼河がそれであり、遼河から分岐した支流が先に上げた名前になるのだろう。尚、この時期の史書に帯方郡が出てこないのは、帯方郡を楽浪郡から分離する前だからである。
結論は本紀巻一下洪武帝の所にそのものずばり書いてあるとおり、「樂浪郡,故朝鮮國也,在遼東」である。翻訳すると「楽浪郡は嘗ての朝鮮国であり遼東にある」となる。漢4郡はこの朝鮮国を分割してできた。当然邪馬台国への道の起点となる帯方郡も遼東にある。
つまり史料批判以前に資料をきちんと読んでなぞ無く、古朝鮮(箕氏朝鮮)を半島に置いたが故の大勘違いという事になる。実際小竹に拠る漢書訳文地誌下の楽浪郡も何の根拠も無く朝鮮半島にあると書いてある。ありもしないことを勝手に書くなと言いたい。
参考文献
契丹古伝全文はこちらからどうぞ。衛満こと衛瞞の話は34章に出てくる。その内容は漢と組んで箕氏朝鮮を滅ぼしたという話になっている。
この後東胡辺りが遼東を襲撃する話が出てくる。今にして思えば匈奴が漢を襲撃し続けたのは中原がかつての故地だったからではないだろうか。契丹古伝が伝えているは扶余や東胡、後の靺鞨などが抑も中原を支配しており、その後西から侵入してきた漢民族によって中原から追い払われた。彼らが言うには殷は内部から崩壊させられた。偽作ばかりと言われる古史古伝の中ではまだ信頼性が高い方である。
契丹古伝第40章を引用する。翻訳は引用元を参考にした。
洲鮮記曰。乃云訪于辰之墟。娜彼逸豫臺米與民率爲末合。空山鵑叫、風江星冷。駕言覽乎其東藩。封焉彼丘不知是誰。行無弔人、秦城寂存。嘻、辰沄氏殷、今將安在。茫茫萬古訶綫之感。有坐俟眞人之興而己矣。
洲鮮記に曰く。乃(すなは)ち云(ここ)に辰の墟を訪(おとな)ふ。娜たる彼の逸豫臺米(いよとめ)、 民を與し率いて末合と為す。空山(くうざん)に鵑叫んで、風江に星冷たし。駕(が)して言(ここ)に其(そ)の東藩を覧みる。彼の丘は封じ焉(おわ)り是(これ)が誰(たれ)なるを知らず。行(みち)に弔う人無く、秦城(しんじゃう)寂(じゃく)として存す。嘻(ああ)、辰沄氏殷(しうしいん)、今将(ま)た安(いづく)にか在ある。茫茫(ばうばう)たる萬古(ばんこ)の訶綫の感。有(また)坐(そぞろ)に真人(しんじん)の興るを俟(ま)つのみ。
洲鮮記が伝えるには、そうして、(『洲鮮記』著者である自分は)辰の廃虚を訪れたのである。娜たる彼の逸豫臺米は、 民を預かり率いた後に合流した。人のいない山では鵑(という鳥らしい)が哭き、風が吹く皮を照らす星の光が冷たい。嗚呼、辰沄氏殷は今どこにあるのだろうか。茫々たる萬古の訶は細長い糸のように感じる。またそぞろに真なる人が起きるのを俟つだけである。
つまり殷の廃虚を訪れた著者は次のように書いている。
殷の廃虚をを訪れた。あの美しく優雅な壱与臺女は民と協力して国を治めていた。今や廃虚には鳥の鳴き声が聞こえ、冷たい星の光が風が吹く川を照らしている。ああ、かつてこの地を治めたであろう(辰沄氏)殷はどこに行ったのか。大昔からの歌(詩)は細い糸のように続いている。また天命を受けたものが起きるのを待っているだけである。
まぁ、滅びた国家の栄華を偲び、誰かが殷を復活させてくれないかと書いているわけである。
だがここで重要なのはここで出てくる逸豫臺米(いよとめ)である。あの卑弥呼の宗女壱与と似た名前である。この著者が訪れた先が中原かそれとも遼東かは不明である。少なくとも邪馬台国と言われる場所でないことは確かだろう。
契丹古伝はいくつかの書籍からの引用から成り立っており、その一つが「費彌國氏洲鑑」、費彌國は「ひみこく」と読む。洲鑑はその国の記録という意味だろう。また「耶馬駘(やまたい)記」というのもある。どこかで聞いた名前()だが、古史古伝が社会的に認められてないことを考えると無視されるのがオチだろう。
2025.12.21 加筆。調子に乗って契丹古伝について書いたら長くなってしまったw
古代日本における船舶についてのメモランダム
日本の古代史上で余り語られない輸送について考えてみる。
縄文時代までの輸送方法については、あまり語ることはない。何故なら徒歩の場合、荷物を直接担いで移動するより他なく、一日当たりの移動距離は100キロとないからだ。現代の軍隊では一日40kmを目安にしている筈だが、ほぼ平坦な地形ばかりならそれでもいいだろうが、日本の地形を考慮する場合30kmも移動したら多い方だろう。近代迄は牛馬に荷物を括り付けて牽いていたから、移動距離は多少伸びた程度と思われる。
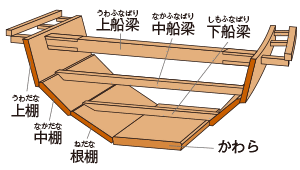
海上を移動する場合、主に船が使われる。弥生時代まではほぼ丸木舟が使われていた。しかし丸木舟の積載量は元の木材の大きさに拘束される。そこで、船の容積を増やす為、よく言われているのが準構造船である。我が国では下図のような準構造船(1)がよく紹介される。

この時板の継ぎ目にはZ型の部材を嵌め合わせることで上下方向に抜けないようにする。ただ左右(板厚方向)の力に対しては弱くなるので、ダボを入れる必要があるが、著者の知る限り古代の船舶でこのような構造を入れたものは知らない。
板の継ぎ手形状を以下に示す。右は上下の板の継ぎ手である。最初は下に示すようなダボかもしれないが、一般的には角材でつないでいる。


しかし準構造船(1)の構造だと凌波性は多少向上するが、積載量は元になった丸木舟の制限下にある。その制限から解放されるには準構造船(2)の様に幅も広げる必要がある。勿論板のつなぎ方は上に示したものを用いる。
今のところ準構造船(1)だけしか発掘されていないようだが、より多くの荷物を積載するには準構造船(2)のような構造が望ましい。
この後構造船に移行するはずだが、これも発掘されていない様である。この結果、船の構造は大陸から来たと言いたげだが、中国大陸の沿岸などほぼ静水状態である。つまり波がない。特に渤海は波が全くない海として知られる。だから中国は大型船を容易に作ることが出来たと言える。
しかし中国の船では外洋を航行することができない。船底が平板なので凌波性に問題がある。特に楼船ともなると速度が出ないので、中国沿岸から対馬海峡に差し掛かるとそのまま日本海に流されかねない。まぁ、彷徨える中国人が出来上がるわけである。
ではわが国でこのような構造船が作られただろうかというと確証がない。何しろ推定はできるが発掘資料がない上に、考古学者に船舶について知っている者がどれくらいいるのかという疑問もある。寧ろそちらの方が重大だが。
しかし日本が構造船を作る必要性はある。準構造船(2)の発展形で、中央の底板(瓦という)を厚く重くし、その両脇に板材を並べる。例えば参考文献1から引用した下の左の様な構造になる。
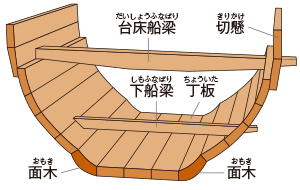
では構造船が必要になる理由は何か。それは鉄と馬の輸送である。馬というのはかなり神経質な動物らしく、JRAの運送車両などほぼ窓ない特異な形状をしている。

この様な動物を海上輸送するにはそこそこの大きさの船体が必要であり、厩舎を甲板上に設ける必要があるだろう。また海水が厩舎に入り込まない工夫も必要であり、航海中、余り船が揺れないようにする必要もある。しかも、馬は寒冷地向けの動物なので、海上輸送は春の内に行うべきとなる。また輸送するなら数匹輸送出来たほうがいい。
そう考えると丸木舟や準構造船(1)のままでは馬匹輸送を行えないことが分かる。また鉄を輸送する場合、抑々重量があることや、海風による腐食を考えるとこちらも船上の建屋が必要になる。
恐らく古墳時代辺りには構造船を完成させていたのではないかと思われる。問題は発掘資料がない事である。なお、船舶埴輪の類は余り実構造を反映していな可能性が高い。この傍証としては明治初期の鉄道錦絵である。当時最新鋭の陸上移動手段を記事にするのが主目的なのか、実物を模したものであるとは限らないのである。況してや太鼓の埴輪なので、実物通りと考えるのは危険である。
結局、実物の船舶の構造を参考にして、太古の日本人はどのような構造の船を作ったのかを考えるべきである。
追伸:対馬海峡を良く突破する実験をしているが、あの急流を横断するのではなく、五島列島から北東に進んで巨斉島を目指した方が渡海は成功する筈である。韓国からも同じく巨斉島を起点とし、対馬に向かった方がいいだろう。その方が海流を利用できるはずである。
参考文献
和船はどのように発達したか│54号 和船が運んだ文化:機関誌『水の文化』│ミツカン 水の文化センター
陸蒸気からひかりまで 機芸出版社
明治の貨物列車に馬運車が含まれているが、車体には窓一つない。
白村江の戦い 無条件降伏論を嗤う
白村江の戦いの結果日本は無条件降伏したというショッキングな論を見かけた。何をもって無条件降伏をしたと考えているのか不明だが、どうやら当時の文書を解読するとこういう結論になるらしい。しかし、無条件降伏論には根本的な無理がある。
まず、当時唐に潰された百済と高句麗がどうなったかを考えてみればわかるが、王族と貴族は本国に拉致されている。つまり伝統と正統性を破壊する訳だ。そして、復興運動など二度と起きないようにする。それでも起きるのが復興運動だがいずれも失敗した。
我が国はどうだろうか。皇族も豪族もほぼそのまま残置している。無条件降伏したとなればこれらが残っている筈はない。何か第二世界大戦後のGHQの統治を基準にしているが唐はそこまで甘くない。無条件降伏の暁には確実に皇族と豪族の類はこの世から消され、最終的に文化の類は中国のそれに置き換えられる。
唐は百済・高句麗・新羅・倭に都督府を設置する。前二者は唐の版図同様だから都督府を置く意義はあった。これらの都督府は版図とした領土の監督の為の機関だからだ。しかし、新羅に設置した都督府など最早意味不明である。唐は新羅と同盟を組んでいたし、新羅は唐から柵封を受けていたから、出先機関が必要なのは分かるが、都督府長官と言うべき地位につけたのは新羅国王である。この都督府は名目上のものとされているが、これなら設置しない方がいいし無意味迄ある。これでは新羅の反発は必至で、この後新羅と唐は対立し、旧百済領土は新羅に蚕食された挙句、結局新羅のものとなった。
この都督府、日本の筑紫にも設置され、中国人が務めることになったのだが、百済と高句麗の例を引き合いに出して、無条件降伏したと言っているとしか思えない。その一方で、無意味な鶏林都督府(新羅に設置した都督府のこと)は堂々と無視する。名前が全部同じだから、中身も同じという事なのだろう。だが、新羅は同盟を組んだだけであって唐に制圧も何もされていない。
次に日本での例を検討する。白村江の後、最大4度(うち二回は重複記事とされ3回とする意見もある)唐から使者が来ているが、最初の使者(663年7月ごろ来任)の出したお手紙はきっぱり跳ね付けている。戦争に負けたとは微塵も思っていなかったのだろう。いや、戦争に負けたがそれは出先のことで本土で負けたわけではないから、強気でいられた。そういうことだと思われる。それでも10月に使節団を歓待し、12月にこの使節団は帰任している。時期を考えたら生還できるかどうか怪しいが、この後も日本に来ているから大丈夫だったんだろう。この使節団は130人からなるが、本体30人で残り100人は船の漕ぎ手などの類である。大体本気の占領統治ならこの人数は少なすぎる。というか日本制圧などできない。
唐はこの後新羅と対立したが、百済の時とことなり渡洋侵攻をしていない。というか、百済制圧の際にしか渡洋作戦をしていない。これが意味することは明白で、唐といえども渡洋作戦は負担が大き過ぎたのだ。渡洋作戦を行うには通常の遠征同様補給物資の他、更に船舶の建造と漕ぎ手の確保が必要になる。更に移動中の損害を見込む必要がある。これが第二次世界大戦なら、敵の妨害だけを考慮すればいいだろうが、古代の場合、天候や波浪を考えないといけない。つまり送り出したら皆戦場に来ませんでしたなんてこともありうる。それ位、渡洋侵攻のリスクは高いのだ。
唐は白村江で勝利はしたが、二度と渡洋侵攻を行わなかった。つまり一度で懲りたという事である。勝利してこれである。であれば日本に渡洋侵攻など、それこそ、控えめに言ってもリスクしかなく、最悪行って帰ってこない鉄砲玉状態になりかねない。また、船舶と漕ぎ手全損となったら通常の陸上戦闘以上の損害になる。
話を戻すと、次の使節団は254人である。都督府の設置はこの時決まっただろうが、占領統治なら最初の使節団の来日の時点で一方的な都督府の設置通告を受けるはずである。だが都督府が設置されたともされていないとも書いていない。筑紫都督府の存在が確実なのは667年だが、671年は筑紫大宰府に名称を変えている。日本制圧するにも人数が全く足らないのはさっきと同じである。これで日本を制圧できたとするなら、クビライ・カンはタイムマシンで唐に来て高宗にどうやって日本を制圧したのか聞きに来るだろう。それとも無色透明な架空の唐の大艦隊でもあったのかと言いたくなる。
最後の使節団は2000人の規模に膨れ上がり、これまでの例を参考にすると1400人余りが漕ぎ手などになる。それでも600人の規模である。人数が増えた理由は多分交渉に業を煮やしたか、筑紫都督府の稼働の為だろう。実際これまでは筑紫で足止めを喰らっていたことが確認される。実際にこれまで飛鳥などに唐の連中が来たという考古学的な証拠なぞ存在しない。そして当然日本制圧をするにしても絶望的に人数が足らない。
さて、この後の高句麗はどうなったかというと地元の高句麗系住民の慰撫の為に高句麗王を封じたはいいが結局靺鞨と組んで高句麗復興運動を始めたものだから、唐はその運動を潰し、元国王は流刑に処した。旧百済領に設置した都督府はこれも意味がなく、結局旧百済領は新羅に併合された。こんな有様だと都督府って何のためにあるのかと思う。尚新羅に設置した都督府に至っては存在意義すら分からないものだった。
なら日本に設置したものは何となるが、どう考えても出先機関である。説明を見る限り軍政もやるような組織という事になっている。特に筑紫都督府はその方面の人数が少ない。これで無条件降伏というのは無理があり過ぎる。無条件降伏をしたらどうなるかは先に書いたがそうなっていない。そうなると根拠は何かとなるが、この都督府の存在という事らしいが、その実態が単なる出先機関である以上、どう考えても無条件降伏論には無理がある。
確かに朝鮮半島での一連の戦乱の敗北はそれなりの衝撃だっただろうが、その後の行動についても、唐の言いなりに必ずしもなっていない。例えば唐の高宗が儀式をやる事になったが、そこに来た日本代表には皇太子の類は含まれていない様である。というかどこの史書もはっきり書いていない。でていたら何らかの資料が残る筈だから、結局日本の皇族は誰一人参加していないことになるだろう。
これも無条件降伏論の欠陥で、唐の言いなりだったら節度使は筑紫に足止めなどされていないし、飛鳥に入れたはずである。また当時の交通状況や通信状況を考えると筑紫から飛鳥の制御など不可能である。
彼らの軍事的識見の欠如を挙げると白村江他と一連の戦闘で日本軍は全滅したという主張である。しかし、戦後百済遺民が最大5,000人来日している。その中には鬼室福信一族も含まれる。とすれば護衛の兵力もいた筈で、白村江などの戦死は10,000とすると、派遣人数27,000からこの数字を引けば最大17,000が帰還できたことになる。勿論撤退中に戦死したものなどもいるからこれより少ないだろうが、日本に戻った人数は最大22,000となる。これが現実で全員かの地で死に絶えましたなどありえないのが分かるだろう。
もう一つは戦後に遷都した近江宮の件だが、この都の防衛は周辺の地形を利用したものなのは地形を見れば一目瞭然である。例えば瀬田、逢坂、倶利伽羅峠と言ったところで敵の侵入を防げれば防衛線には勝てる。実際の壬申の乱ではそれに失敗した故に大友皇子は敗北し、自害することになった。両者の兵力が拮抗した場合、普通防衛側が有利の筈だが、そうなっていないのは、それ以前の戦いでの損害を補えなかったか、結局大海人皇子の方が兵力で優越したかの何れかだろう。そのルートも吉野から大回りをして尾張辺りに出ると、不破関→瀬田橋(最後の決戦場)と進んでいる。また一部部隊は琵琶湖北岸を進んで大津京に向かっていた。大友皇子は不破を抑えるつもりだったのだろうが、内部の混乱でそれが出来なかった。恐らくここから瀬田までは撤退戦闘だった筈である。そうなると士気が落ちるが、大海人皇子側は進撃するから士気は上がっただろう。
結局、近江宮自体を守るのではなくその外側で敵を迎え撃つのが主目的だから、防御力など初めからないのである。こういうことは周辺地形を見ながら勘案すべきである。結局大友皇子は初期の防衛構想を実行することが出来なかったのだ。
以上が白村江の敗戦後の無条件降伏説などありえず、石井らの書いたものは単なる戯言であることの論証である。そこに見えるのは軍事的地理的識見の欠如であり、さらに政治的な条件をまるで考慮していない暴論の展開である。
また都督府の設置を持ってGHQと同じとかも妄説の類でしかなく、自分の都合のいいようなこじつけをしているだけである。それは学問とは言わない。
参考文献
日本の古代史を考察したサイト。白村江関連の年表はここを参考にさせていただいた。感謝します。
白村江の戦いの後の日本を考察した論文
https://iush.jp/uploads/files/20241127103244.pdf
無条件降伏論者のサイトその1。だいたい、引用した書籍の著者を間違えている(ともに工学関係で日本古代史とは何の関係もない)し、唐からの使者の人数254254人とか金輪際あり得ない数字(多分誤記)をのせている。これなどまだマシな方で、もっと糞なサイトが実在する。電波浴をしたい人は探すといいだろう。
日本古代史ネット【特別保存論文】|白村江の敗戦 と 唐による倭国の 羈縻(キビ)支配
この手の想像力が豊か過ぎる方々は何でも唐がLST(強襲揚陸艦)を保有していたなどと書くが、この手の艦船を最初に建造したのは大日本帝国陸軍である。ここ迄くると知識のない無能は黙ってろと言いたくなる。
2025.12.21 誤字訂正
白村江の後始末()
白村江の戦いの概要をWikipetiaから引用する。
白村江の戦い(はくすきのえのたたかい)は、天智2年8月(663年10月)に朝鮮半島の白村江(現在の錦江河口付近)で行われた百済復興を目指す日本・百済遺民の連合軍と唐・新羅連合軍との間の戦争のことである。
結局この戦争にボロ負けした日本に唐からの使者がやってきた。まぁ戦後処理だろう。尚、この使節団の人数は約2000人で、内訳は使節団600人、護衛のつもりの軍人が1400人である。人数多すぎないかと思うが、当時の船舶でよく来たものだと思われる。まぁ、唐は一応黄海を横断したらしいので、その程度の外洋航行能力があったものと思われる。
まぁ、万歳突撃の様相を呈した海戦とすら言えないことをやって一方的な敗戦を喫した側が言えたものではないだが。
で、この交渉は結局日本側が唐に贈り物をし、遣唐使の派遣を約束(実質的に朝貢)することで決着を見たのだが、この唐使節団の出航時期が問題と言えば問題である。
交渉団は6月に到着し、10月に使節団長が出国している。10月である。当時は旧暦だから今の暦で10月下旬から12月上旬である。つまりこの時期の玄界灘は荒れた状態になっているから、さぞや思い出深い航海になっただろう。天智天皇以下満面の暗黒微笑で見送ったことは想像に難くない。
で、合計2000人もの「駐留軍」(実質的には増強された大隊とでも言うべき1400人だが)が居座るわけだが、この人数で日本制圧は不可能である。まぁ、日本に来たからそのまま追い返せる筈もなく、駐留を認めたのだろう。敗戦国史観塗れの中村修也立教大学教授の如きは下にある様にとてつもない妄想を掲げているが、軍事的識見と地理条件の識見の欠如がなければこんな妄想文章を書くことなど不可能である。大丈夫か?文教大学。
まず来日だけでも一苦労である。この当時の唐と雖も玄界灘を平気で突破できるような船舶の持ち合わせなぞありはしない。皆、船酔いで悶絶するのは確定的に明らかである。また日本制圧をするにも人数が全然足らない。九州を制圧するだけでも二桁足らない。こんなんで日本制圧が可能なら蒙古に負けてるわと言いたくなる。
あと朝鮮半島から太宰府辺りまで狼煙台を作ったとか言ってるが距離を完全に無視している。狼煙の有効範囲など10キロもない。つまり壱岐や対馬に狼煙台を作っても、まるで意味がない。まぁ、灯台を建てたほうがいいと思うが。こんなことも知らんといけしゃあしゃあと書く中村はバカだろ、と言いたくなる。これで教授とは目出度い奴としか言いようがない。頭ハッピーセットかよ。
この部分は言葉が過ぎた。きちんと調べると最大200キロから視認できるとのこと。訂正の上、過激な言葉を使ったことをお詫びいたします。
結論。白村江でボロ負けしたのは事実だろうが、戦後処理をするにも唐の大軍が日本に来ること自体命がけである。つまり「やりたきゃやれよ」でもいいだろうが、そこは辞を低うして礼を厚くして歓待し、贈り物と遣唐使の派遣を約束する。まぁ及第点じゃないんですか?国内では危機感をあおり、海外にはどうせ侵攻不可だろうから、ある程度強気で交渉ができた。それが事実だろう。
参考文章
2026.1.7 訂正
邪馬台国の真実 其二
題名で大見えをきったので、疑問だけではなく、邪馬台国の位置を考察することにする。
前回は邪馬台国以前に後漢書などの記述から邪馬台国国内説についての疑問を提示した。その内容は次のとおりである。
山海経では、北から燕・蓋国・倭の順にどうも地続きと受け取れるような記述がある。これだと倭は日本国内ではなく、遼陽以南にあることになる。
漢書では楽浪海中に倭人が住んでいるという。楽浪海という用語は存在しないが、楽浪郡は存在した。楽浪郡というのは元の衛氏朝鮮を滅ぼした土地を四分割した内の一郡である。邪馬台国への行程を記した帯方郡とともに朝鮮半島内にあるのが通説になっている。だが漢書の記述を真に受けると、倭は朝鮮半島にあることになりかねない。
後漢書には邪馬台国が出てくる。なんでも大倭王なるものが統治してるとのことだが、後漢に朝貢するのは邪馬台国の大倭王ではなく倭の南端にある奴国である。最初に金印を貰い、次は生口160人を献じたとあるが、生口が何であるかは論じても、どうやって日本本土から丸木舟だけで160人輸送したか論じたものはいない。当然輸送にあたっては玄界灘の荒波を考慮する必要があるが、そうなると輸送など事実上不可能である。何しろ当時は丸木舟しかない。
この金印についても疑問がある。金印の真贋論争は面白いが、どうしてあのような形で埋まっていたのかを論じたものはいるのだろうか?まるで封印である。
次に隋書倭人伝を取り上げる。この中で隋からの使者が阿蘇山について質問する箇所がある。しかし、よくよく考えると日本固有の地理情報について記述したのはこれだけではないのか。何故他の倭人伝には火山や温泉の情報がないのだろうか。無論神社でもよい。そうなれば古代日本にとって重要な情報となっただろうが、そういうものは一つたりともない。まぁ、時期が時期だから今のような神社があるとも限らないのだが。
つまり当時の中華帝国から見た倭というのは日本本土でない可能性が高い記述ばかりである。当然邪馬台国も日本本土にないことになる。 日本に来たにもかかわらず固有の地理情報がない。例えば、別府温泉や関門海峡、出雲大社(約50mの建物を目にして書かない筈がない)、瀬戸内海の状態。これらを全く欠いている。
そこで、起点となる帯方郡の位置から考えることにする。帯方郡北方には楽浪郡があるが、魏志倭人伝によると単単大嶺の付近にあることが分かっている。この単単大嶺が長白山脈とすると凡その楽浪郡の位置が定まる。帯方郡はその南側となるが、問題は単単大嶺が標高1000m~2000mの山脈だという事である。拠って楽浪郡も帯方郡もこの山脈を避ける必要がある。地図上では行政区分に含まれるだろうが、この辺りまで統治は及ばなかったと考えられるからだ。最も当時は正確な地図などないだろうから、凡そこの辺り位までとなるのだが。
魏誌東夷傳全体を読んで大体の位置を推測すると下図のようになる。

図にはほぼ全員が無視している地形情報を入れておいた。茶色で囲んだ部分は大体標高1000mの範囲を示しており、長白山脈に至っては標高2000mの部分もある。単単大嶺は韓国東南部にもあるが、中国から見た単単大嶺は今の長白山脈である。この地形情報は非常に重要で通常大軍を投入しても行軍に難渋する。事実、唐により第三次高句麗討伐で高句麗を滅ぼすまでは、連戦連敗の有様だった。成功したのは毌丘倹の討伐位である。
まず楽浪と帯方の二郡は定説より北に配置した。こうすると多くが無視している高句麗に拠る西安平侵攻のルートをすんなり説明できる。この侵攻では楽浪や帯方郡を経由しているが、通説だとこのルートの説明が出来ない。抑々公孫氏を滅ぼした時遼東と遼西、そしてこの二郡は魏に戻っている。定説通りの場合、山を越えた向こうまで手を伸ばせたとは思えず。伸ばすにも遼東半島の細い回廊位しか道がない。そして在半島勢力がこの状態を指を咥えて見ているとも思えない。これも誰も指摘しないのだが、平壌からソウルまでは朝鮮半島では平野が広がっている地域である。
実際の地図は次のようになっている。半島の西側に比較的平原が広がっているのが分かるだろう。中朝国境は比較的低地に見えるがこの辺りは1000mの産地である。
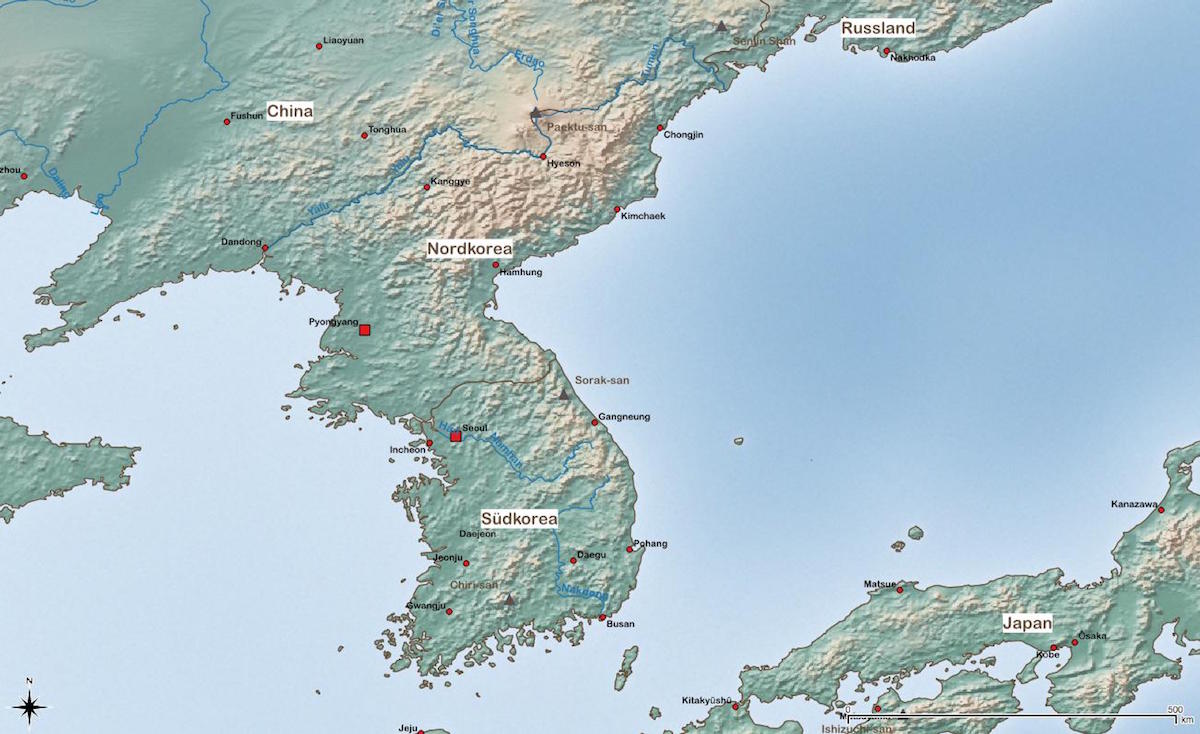
この図と比較すると帯方郡は遼東半島北部から遼河南岸辺りまで食い込んでいると推測できる。何度でも繰り返すが、中朝国境はそう簡単に大軍が突破できる地形ではない。
さて中国から見た倭という観点で見てみよう。中国から半島を見ると、「倭は韓の東南の大海の中に在り、山島に拠りて居を為』となっていないだろうか。中国大陸から朝鮮半島を見ると当然山脈が見える。倭人はその麓に住んでいると描写しているわけだ。
このように考えると倭人伝の内容は何ら矛盾していないことになる。これも前回指摘したが各倭人伝の著者が出鱈目を書く理由は存在しない。皇帝の面子を潰すような内容は書けない(リアルで首が飛ぶから)が、東夷のことなぞ態々出鱈目を書く理由がない。寧ろ日本本土から朝貢の使者が来たら陳寿以下倭人伝の著者は喜び勇んでそのことを書くだろう。何故なら、なるべく遠くから来てくれた方が時の皇帝の徳を高めることになるからで、ならそのことをきちんと書いた方がいいことになる。なのに現実は行程の記述がいい加減と言われる始末である。第一隋書倭人伝迄日本国内の目星になるものがまるでないというのもおかしい。
例えば対馬と壱岐だが、魏志倭人伝では、其々対海国と一支国となっている。何故か後年の写本では対海国ではなく対馬となっているが、これも混乱の元である。気を利かせたのが逆に間違ったことをした、いい例である。この面積はそれぞれ400里と300里四方となっているが、面積比は2:1程度である。だが対馬の面積は壱岐島の3倍以上ある、この乖離の説明もない。また壱岐島は実は自給自足が可能だが、この当時それすら出来ない島となっている。壱岐島南部は海岸線が複雑になっているから、それなりに有用な漁場の筈だが、そうなると米の生産量がそこそこあれば島民の食い扶持は稼げそうではある。事実、後年対馬の防人用の米を全部壱岐から出してくれという依頼が出ている。この為には水田の追加開発が必要だが、そうなると結局自給自足できていたことが分かる。また対馬と壱岐の間の海を瀚海と名付くとあるが、この間の海は何か閉じたものではなく大海の中に浮かぶ島の間である。別に名前を付ける様なものではない。
次に末盧国を取り上げる。この国は長崎県松浦市に比定されているが、抑々なんで博多湾の方に案内しないのだろうか。その方が外国からの使節団の案内に適切である。現実の3世紀の松浦ははっきり言って松浦湾周辺に村があるだけで、その先の道など獣道もいいところだろう。それ処か歩けるかもどうか怪しい。
で、魏の使者がどうやって日本に来たかとなると、当時の日本には構造船はない。まぁ、一応魏の船を使うことになる。当時の魏には構造船があるのだが、玄界灘を突破できるかどうかも怪しい。それ位外洋航海のハードルは高い。まさか丸木舟や舷側を継ぎ足した準構造船如きで魏の使者を運んだという気だろうか。これもかなりハードルが高いのだが、張政ブチ切れ必至である。まぁ、その前に船酔いで悶絶するだろうが。
我が国の考古学者やマニア共はこのようなことをまるっきり考えずに国内説を主張しているのである。
そういう訳で邪馬台国日本国内説などさっさと破却し、妥当と思われる位置を推定すると次のようになる。

投馬国は現在のソウル付近、邪馬台国は太田付近となる。この辺りは日本の弥生時代としか思えない遺跡も出土しているからこれでいいだろう。ここでなくともこのルート上のどこか、という事は確実である。
大方の邪馬台国論者は魏志倭人伝、正確には正史三国志烏丸鮮卑東夷傳倭人条だけを読ん国内のあちこちを邪馬台国だぁ!と書いているわけだが、東夷傳全部をきちんと読んだのかと、そして丁寧に位置関係を調べたのかと問い詰めたい気分である。何というか明治に邪馬台国埃及説を唱えた木村鷹太郎の気持ちが分かる。彼が言いたかったのは名前の類似だけの牽強付会からの位置特定など凡そ学問とは言えず、天下の大愚物とまで罵倒している。そりゃそうである。
彼ら知識人は我々とは異なり、史記からの各種書籍を読めた筈である。新井白石もだが、何故それら総てを読んで総合的に判断しなかったのか。軍事や地理等の条件を加味した場合帯方郡は定説の位置にならない。それはこれまで検証した。
倭も邪馬台国も抑も朝鮮半島にあれば陳寿が書いたものは摩訶不思議なものではなく、無理なく説明できるものである。つまり出発点が間違っていたのだ。これもどうも後代になると朝鮮の位置の誤謬(箕氏・衛氏朝鮮は今の朝鮮半島になかった)を真に受けた結果である。凡そ海外からの文物の受け取りに際しては中身をきちんと検証する姿勢が欠けてるから、この様なことを晒すのである。
2025 12/21 一部文章と誤字訂正
邪馬台国の真実 其一
古代日本史最大の謎とも言われる邪馬台国はどこにあったのか?現在、最大手の九州説と畿内説のほか国内いたるところが候補地が挙げられている。
基本的な定本は「魏志倭人伝」、正確には魏誌第30巻「烏丸鮮卑東夷傳」である。以下倭人伝と略す。では、それ以前に倭国なるものについて書かれたものがないのかと言うとそんなことはない。三海経や論衡といった書籍にも倭人に関する記述がある。また邪馬台国について記述された倭人伝以外にも倭人についての記述がある。
まず論衡についての記述をWikipetiaから引用する。
「周時天下太平 倭人來獻鬯草」(異虚篇第一八)
- 周の時、天下太平にして、倭人来たりて暢草を献ず
「成王時 越裳獻雉 倭人貢鬯」(恢国篇第五八)
- 成王の時、越裳は雉を献じ、倭人は暢草を貢ず
「周時天下太平 越裳獻白雉 倭人貢鬯草 食白雉服鬯草 不能除凶」(儒増篇第二六)
- 周の時、天下は太平にして、越裳は白雉を献じ、倭人は鬯草を貢す。白雉を食し鬯草を服用するも、凶を除くあたわず。
越裳と倭がどこにあるかの記述を欠くが、単に周があちこちから貢物を献じられるほどの大国だと書きかかっただけかもしれない。
次は山海経からの引用である。これもWikipetiaから引用する。
「蓋國在鉅燕南 倭北 倭屬燕」(『山海経』第十二「海内北経」)
- 蓋国は鉅燕の南、倭の北にあり。 倭は燕に属す。
燕は中国北方、黄海北方の渤海沿岸にあった国の筈である。蓋国についての記述がないからどのような国か不明だが、倭の北にある。これを読んで素直に考えると、倭は燕と地続きとも受け取れる。海を渡ったのならその記述があって然るべきだからだ。また倭は燕に属すとあるが、日本の歴史上、そんな歴史は知らんとしか言いようがない。
次に同じくWikipetiaの漢書の部分である。
然東夷天性柔順、異於三方之外、故孔子悼道不行、設浮於海、欲居九夷、有以也夫! 樂浪海中有倭人、分爲百餘國、以歳時來獻見云。(『漢書』地理志燕地条)
- 然して東夷は天性柔順、三方の外に異なる。故に孔子、道の行われざるを悼み、設(も)し海に浮かばば、九夷に居らんと欲す。それ、以(ゆゑ)有るかな! 楽浪海中に倭人有り、 分れて百余国を為し、 歳時をもつて来たりて献見すと云ふ。
一方、東夷は性質が柔順であり、他の三方(西戎・南蛮・北狄)と異なる。そのため、孔子は、中国の中原では正しい道理が行われていないことを残念に思い、(筏で)海を渡って九夷に行きたいと望んだ。それは理にかなっている! 楽浪郡の先の海の中に倭人がいて、百余国にわかれており、 定期的に贈り物を持ってやって来た、と言われている。
倭人の国は楽浪郡の先の海の中にあり、また、百余国(といっても今のような国家というようなものではないだろが)に分かれているとある。孔子はそこでは礼節が為されているから海を渡ってそこに行きたい、というようなことを述べているわけである。また、倭人の国は定期的に贈り物を持ってきたという事を書いている。
倭の位置は楽浪郡の先の海の中とある。楽浪郡は定説では平壌付近とされている。平壌付近の海の沖合にでも倭人の国があるという事なのだろうか。屁理屈に聞こえるだろうが、これも楽浪郡の先の海である。
定説によるとどうもこの倭人の国も日本列島を指すらしいが、そうなると少なくとも楽浪郡から見て南東になる。九州に限定すれば南だから、楽浪郡が朝鮮半島全体を指すものでもない限りこの説には無理があるように思える。そして楽浪郡=朝鮮半島全体という公理など存在しない。
さて文中には筏とあるが、何時の文献の引用なのだろうか。調べてみると秦代には構造船があるらしいことが分かる。孔子はその前の時代の人の筈だから、最悪丸木舟での移動となるだろう。筏での移動とかこの時代だと自殺行為でしかない。
更に当時の航海術は島伝いでの移動が一般的だったようである。昼は島影を見ながら航行し、夜はどこかに停泊の形をとる。人数が限られた小型船での移動となるとこんなものである。構造船でも数十人も乗るくらいになると昼夜兼行での移動が可能だが、孔子の時代にそんなものが有ったとは思えない。一応星辰の位置を確認しながらの航行が出来ないことも無いだろうが、想像の域を出るものではない。
当時の航路を考えると、山東半島沿いに航行し、渤海沿岸→遼東半島の順での移動になる。そして帯方郡に向かう形になるだろう。天気が良ければショートカットも出来るだろう。倭国はその海の先にあると言う。定説に従うなら、この先の記述があって然るべきだが、そんなものはない。孔子は倭があることを確信したかのようなことを残しているのだから、凡その位置について記述したのではないかと思われる。この倭が日本列島だとしたら、楽浪郡の海の先などという表現では済まない筈である。もっと時間がかかり、死を覚悟して海を越えたら船酔いで悶絶した先の陸地となる筈だが。
対馬と朝鮮の間には対馬海峡があり、ここは急流として知られるし玄界灘も易々と航海できない場所として知られる。この記述は中国の正史には一切ないが、それ以外の記録にはこのような記述があることから、正史には載せる価値がないとして記述しなかったのかも知れない。
次は後漢書東夷伝からの引用である。出典は鳥越憲三郎の「倭国・倭人伝全訳」である。
倭は韓の東南の大海の中に在り、山島に拠りて居を為し、凡そ百余国也。武帝の朝鮮を滅ぼしてより、使訳の漢に通ずる者三十許の国にして、国は皆王と称して、世々伝統す。その大倭王は邪馬台国におる。
不審なのは、武帝が朝鮮を滅ぼしてから遣いを派遣した国が30程という事である。ここでいう朝鮮は衛氏朝鮮という古代国家で今の半島国家とは当然別物である。当然倭国は日本本土にあるのだから、衛氏朝鮮なぞ無視して朝貢すればいいのではと思うが、誰もそんなことは指摘しない。そういや魏志でも公孫氏を滅ぼしてから邪馬台国が朝貢に来たという話を載せているが、よくよく考えてみれば、適当に話を通しておけば妨害すらないと思われるが、誰一人としてそんなことは言わない。まぁ、通常の航路を考えると、韓国南部に到着した後真直ぐ西進すれば中国大陸に到着する。衛氏朝鮮にしても公孫氏にしても中国皇帝への兆候を妨害していたそうだが、日本国からの使者迄妨害するもんだろうか。
先に上げた航路にしても無理がありそうだが、縄文人の航行能力をもってすれば比較的容易だと思われる。え、今は弥生時代だって?縄文人は本土↔神津島の往復をしていた。この間ほぼ陸地は見えない筈である。どうやって航海したのかは分からないが、その経験があれば韓国南部から中国本土への航海など弥生人でも容易だろう。下手すると、朝鮮南端は只の経由地の可能性も考えられるし、そうなると朝鮮半島南部西岸が海の難所であることを考えるとほぼ妨害の可能性はない。
このように考えると適当な船舶があれば九州から中国までの航行が不可能ではないと思われる。問題は対馬海流だが、壱岐島から北西に進めば中国本土に到着することは容易だろう。こうなると朝鮮半島の政治情勢は完全に無視できる。
問題はこの当時、日本にあったのは丸木舟か準構造船という、丸木舟の両舷に板を継ぎ足したような形態をしていた。準構造船の場合やりようによっては航海できないことはないが、かつての実験を見る限り、船舶の構造を本当に検討できていたかの疑問が残る。あれは、前後に大型の波よけ板らしきものを設置していったが、ざっと見、単なる死重にしか見えない。また推進力を生みだす場合、人力(櫂で漕ぐ)か帆船にするしかないが、この櫂で漕ぐのすら不自由する構造だった。
楽浪郡の徼は、その国を去ること万二千里、その西北界の狗邪韓国を去ること七千里なり。その地は大較会稽・東冶の東に在り。朱崖・儋耳と相近く、故にその法俗は多く同じ。
一理がどのくらいあるか知らないが一里80mとすると万二千里と七千里はそれぞれ約960km、約560kmとなる。しかし、この当時は正確な測量など不可能である。よって直線距離での測定は無意味である。今の我々は正確な地図を有しているが、当時そんなものはない。我が国の場合、伊能忠敬が中心になって作成した日本全図で初めて正確な地図が得られた。それ以前は行基図で、ある程度我が国の形を反映していたが、正確なものではなかった。古代中国での地図の歴史は分からないが、今のような正確なものだという保証はない。
この後の「会稽・東冶のの東」とか「朱崖・儋耳と相近い」も凡その位置の描写と考えた方がよく、真東にあるという意味ではないだろう。何度でも繰り返すが、この当時正確な地図は存在しない。どうやって東方にあると判断したのか不明だが、実際の会稽・東冶から見た日本列島の位置は東と言うより東北に近い。古代ならこれでも東としても不思議ではないだろう。
次に30か国が使者を送り込んだとあるが、対馬海峡を通過するのは先に書いたように困難であるし、これなら30か国連合で一括で貢物を送った方がいいのではないだろうか。まぁ、邪馬台国を取り上げる迄もなく、仲の悪い国があってもおかしくないが、だからと言ってバラバラに来られても困るだろう。大倭王がいるならその大倭王の使いだけが来ればいいのにと思うが。
この後倭国の風俗などの記述が続き、それから例の金印を貰った話が出る。この部分はこのようになっている。
建武中元二年(西暦57年)、倭の奴国、貢を奉りて朝貢し、使人は自ら大夫と称し、倭国の極南界也。光武は賜うに印綬を以てす。
安帝永初元年(西暦107年)倭国王師升等、生口百六十人を献じ、請見を願う。
大倭王のいる邪馬台国どこ行った。始めに邪馬台国というのが存在し、さもこれらの小国を統べているかのようなことを書いてきたのに朝貢に来たのはどこまで関係しているか分からない奴国である。邪馬台国にいる大倭王は単にそう名乗っているだけの存在ですか?
中元二年の朝貢の結果印綬(例の金印)を貰ったが、江戸時代に志賀島で発見されたものがそうだと言われている。因みに奴国は倭国の最も南(極南界の意味がこれ)にあると書いている。これも無視されている気がするがどうなんでしょうかねぇ?ここが九州だと邪馬台国と仲が悪いことで知られる狗奴国があった筈だが。狗奴国の近隣に奴国がある場合、政情不安になりかねないから、そこから使者を送り出す合理性がない。え?奴国は北九州にあるって?そこは極南界(南の果て)と言わんだろ。
永初元年の朝貢は誰一人として何も言わない点で更に悪辣である。言われているのは生口が何かという事だけである。生口は良く奴隷と言われているが、奴隷なら奴婢という語を使えばいいだけであって別の語を使う理由がない。よって他の文献から捕虜奴隷か流民の類(新羅本紀で使われている)と思われる。生口の使用はこの後の倭人伝でも同じである。奴婢が登場するのは卑弥呼死後の殉葬者の所で、殉葬には奴婢百名が充てられたとある。大体、いきなり言葉も風習も異なる者百六十名を送り付けられても漢が困るだろう。つまり現実には使い道がない。だが、だが、元中国大陸出身者の流民(多分漂流者)なら、送り付けても問題は少なくなる。
しかし、次はもっと問題である。どうやって160人を輸送したのかについて触れたものは皆無である。当時の日本には構造船は存在しない。従って準構造船という事になるが、この様なものを多数用意しなければ生口160人を運ぶことはできないだろう。というのは生口の他、生口の監視も必要になる。そして準構造船はそのような用途に向かない。よって構造船が必要になるが、そのような出土例がない以上存在しないという仮定を置いて差し支えないことになる。
日本古代史全般に言えることではあるがロジスティックについての検討が殆ど見られない。例えば古墳だが、その材料をどこからどこへ運んだか迄は分かっても、では具体的にどのように運んだかは全く検討されていない。
さて、こうなると次の疑問が湧いてくる。奴国がどこにあったのかという事である。日本国内から生口を運べない以上、奴国が日本国内にあるという仮定を置くことが出来なくなる。これは当然邪馬台国も日本国内にないことになりかねない。また奴国は倭国の極南界にあるというのも問題である。我が国国内では奴国は北九州にあることになるが、この後漢書の記述と真っ向から矛盾している。
女王国より東、海を渡ること千里余にして拘奴(こぬ)国に至り、皆倭種と雖も、而も女王に属せず。女王国より南、四千余里にして侏儒国に至り、人の長三、四尺也。侏儒より東南、船で行くこと一年にして、裸国・黒歯国に至る。使訳の伝うる所は、此に於いて極まる。
魏志倭人伝と異なり、海を隔てて千里(約80km)にある国の名前がある。魏志以降の記述を見るにどうも後漢書を下敷きにし、その時の情報を追加したものと思われる。
ここ迄でもずいぶん長くなったが、ここまできちんと読むと定説が怪しいことが分かる。例えば倭国の極南界にある奴国がそうであり、そこから160人どうやって輸送したのか今もって不明である。前者は定説だと北九州にあるが、そうなると倭国は海の上にあることになる。ソドー島ですか?きっとこういう事を真面目に主張している連中は真水より綺麗な心の持ち主なんだろう。それとも2万年前くらいなら対馬以南が陸地だったからその時の記録について騙っているのかもしれない。真面目に考えると、朝鮮半島南端に奴国があると考える方が合理的である。そうなると帯方郡はそこから1000km北方にあることになる。その位置で妥当とされるのは遼東半島である。

奴国が朝鮮半島南部にあるとすれば後漢書の説明も生口160人の輸送もすんなり説明できる。ほぼ北西に進めば山東半島に辿り着くので、そこそこ大きな船を用意できれば生口の大量輸送は容易である。そしてこの時代の中国はそこそこの船舶を持っていたから、楼船のような大型船でなくとも、数隻程度の船が用意できればいいことになる。
こんなこと書くと当時の記録の信頼性がという声が聞こえてきそうだが、歴代皇帝に不利な情報はほぼ書けない。しかし、外国の地誌ではそんなことする必要がない。距離を盛る可能性があるが、これも如何に遠くから皇帝に貢物を捧げる国があるかという自慢の為ではある。とは言えども余り露骨な嘘を書くと同時代人からの批判が待っている。要は周辺諸国から朝貢が来ればいいとすれば位置についても嘘を書く必要がない。
論衡では倭から貢物を持ってきたという記述しかなかった。この時は正確な位置が分からなかったものと思われる。山海経では倭は燕の南方にあるとあった。それが前漢書では楽浪海中に倭人在りとなる。楽浪海中がどこかは分からないが、この記述の変遷を見ると最初はそういう所があるという程度の認識だったのが、時代が下るにつれ具体的な位置が記述されるようになる。
これが後漢書になるとそれなりに位置の推定が可能な記述や倭の行動が記載される。その位置については先に書いた。通説通りだと後漢書の記述と合わないが、どうしても邪馬台国を日本に置きたいがためにそうしているとしか思えない。更に誰一人として指摘しない生口160人の輸送についても取り上げた。奴国が国内にある場合、技術的に生口の輸送が困難であるとも指摘した。特に学者はこの部分の完全な説明をする義務がある。
魏志倭人伝を著した陳寿が何の考えもなく架空の国名を列挙したとも思えない。どちらも奴国は倭国の極南界にあると受け取れるのである。であれば北九州に奴国があるという定説は否定される。そして話題の邪馬台国は奴国の北にある。当然邪馬台国は日本にないことになる。この他魏志倭人伝の陸行や水行の部分を取り出して、「南じゃなくて実は東」説も破棄されるべきである。邪馬台国に赴いた張政の立場は不明だが、軍人が一人も来なかったとは思えない。軍人も派遣するのは護衛や方角を正確に指し示すためである。そうしないと迷子になりかねない。方角は軍事では重要である。
結局、派遣された魏の役人も陳寿も方角は正確に書いたと考えるのが妥当である。第一定説によると、「帯方郡から海岸沿いに南に東に航行すると狗邪韓国に到着する」と書いていなかったか。それなのに後になって方角が違うとか頭大丈夫かといいたくなる。そう考えると邪馬台国畿内説以下、関門海峡以東にあるという説全部が完全に破棄される。
残るは邪馬台国九州島内説だが、これも奴国の位置が九州北部にないことであっさり破棄される。極南界の意味は南の果てという意味である。九州島だと志布志薩摩半島や大隅半島にあることになるが、ここから態々中国大陸まで行くのは骨などというものではない。
どうしてこうなったか。国内の学者や邪馬台国国内某所論を貼ってい居る連中の史料批判不十分の誹りは免れないところである。元を質すと江戸時代からこの論争は続いているのだが、これも邪馬台国というう国名が日本のヤマトを連想させるところからきているためと思われる。隋書倭人伝になると隋の役人が日本に来ていることが知られる。この時代になると嘗ての倭についての記録が薄れていたと思われる。しかし隋の責任が大きいとは言えない。彼らにとっての外国なぞ所詮関心の外だからである。
この混乱の責任は実は新羅にもある。新羅は最終的に朝鮮半島を統一したが、その時高句麗と百済を滅ぼしている。それには唐の助力があった、と言うか唐以前から大陸の歴代王朝にとって高句麗は不倶戴天の敵だった。つまり何としても滅すべき対象だったわけだ。それと新羅の利害が一致した。そんなところである。それ以前の新羅は倭の下だったから、その黒歴史を消し去りたかった。しかし、史書をきちんと読めばわかるように実は倭は、そして邪馬台国も半島南部にあった訳であり、考古学的証拠迄は消し去れなかった。実際我が国同様の前方後円墳が出土し、人骨は弥生人と同じという結果が出ている。結局自分たちの歴史を直視できない新羅人の末裔にとっての壮大なブーメランという気がしなくもない。
結論など簡単である。きちんと資料を読みましょう。
2025.12.21 訂正。志布志半島なぞないわ。
FEMのプログラムについて、或いは旧FORTRANについて
大晦日になって何でこんなこと書いてるんだと思うんだが、現状があまりに酷いので記事を書くことにした。
筆者の仕事というのは専らFEMによる数値解析で、あまり開発とかやっていなかったりする。どっちかというと計算用のモデルをくみ上げて計算機に放り込んで出てきた結果を纏めるといった程度であって、他の記事で書かれておられるような方々より高度な仕事をしているという訳ではない。
まぁ、実務であれ趣味であれ世の中広いからいろいろ見聞する必要だけはあるんだろうが、井の中の蛙にとってそれは難しい。で、その井の中の蛙からしてみても驚愕というか、唖然と言うか名状し難いものに出くわすことが稀によく起こる。
我が国に有限要素法が導入されて半世紀以上が立つ。初期はプログラムの自作から始まり、現在はソフトウエアを使いこなすことが求められるように変わっていった。
ここで取り上げるのは現在もしつこく続いているらしい、そのFEMプログラムの作成についてである。
平たく言うと50年も経てばプログラミングに求められるものは変わり果てていると言っても過言ではない。初期のころ、つまり自分が垣間見ることすらなかった70年代のコンピューターの能力は今よりずっと低く、その中で効率的な手法を考えざるを得なかった。その最たるものが自己書き換えプログラムというもので、プログラム実行中にプログラムの実行コードを書き換えて別の動作をさせるのである。アスキー版「ハッカー英和辞典」にはその例として「必ず抜ける無限ループ」というのがある。
この例を見てお前は何を言ってるんだという人は正しい。無限ループから抜けるわけないじゃないか。その通り。無限ループというのはあるところをずっと周回するものだから抜けるわけがなく、またどこかで実行位置がループの先頭に必ず戻る。それがずっと繰り返すから無限ループというのである。
このプログラムの作者はアセンブラどころか素の機械語で直接プログラミングをしていた。この時点で今なら正気を疑う人がいるだろうが、当時は当たり前だった。それどころかそうしないと「効率がいい」プログラムを書くことが出来なかった。ここで言う効率と言うのはプログラムサイズと速度の両方を言う。こんなことをするには当然自分がプログラムをしている機械について熟知していないと不可能である。最適化を煮詰めようとする場合などは今でもそうである。
当時のコンピューターの能力はせいぜい80年代の16ビット機程度と思われるので、メモリも多くなかったから、なるべくコンパクトに書く必要があった。速度も当然遅いので最高効率を叩き出すべくあらゆる手段を講じる必要があった。それを達成するための手段の一つが自己書き換えコードである。
で、この必ず抜ける無限ループはどうやったかというと、ループ回数に達するとメモリ上のNOPをジャンプ命令に書き換えるのである。今なら絶対にこんなことは不可能である。多分というか必ず一般保護例外を出してプログラムは終了する。
で、このプログラムをどうやって解読するんだという話になる。コメントなんてものは存在しない。というか入れられない。機械語だけで書かれたコードにコメントを入れることが出来ないからである。解読する方も書いたものと同程度の知識が必要である。そうしないとこのようなものを解読することは不可能だろう。
これが全てでないにしても70年代のプログラム開発というのは、そして少し遅れた80年代のパソコンでの開発というのはこのようなものだった。流石にパソコンで自己書き換えコードは実装されなかったかもしれないが、断言はできない。何しろ「真のプログラマ」はそのようなことを平然と行うからである。それは置くとしても、当時としては実行効率を考えるならアセンブラを使った方が遥かに早かったからである。
註1)アスキー版「ハッカー英和辞典」では「高級言語を軟弱とみなし、スクリーンエディタを軟弱者の道具と見做して自分のコードをデバッガで編集する手合いのことである。
この状況が変わったのが、パソコン上では90年代半ばである。MS-Windows95が登場した辺りから、コンピューターの能力は一気に増大した。まぁ、GUIなんてものを入れたらメモリをバカ食いするし、それ以前にグラフィック自体が資源を食うのでコンピューターの能力を上げないと使い物にならないという現実が横たわっているのだが。
と、ここまで前置きをして、旧Fortranでの開発話に移る。今ならエディタを使用してプログラムを書くのだろうが、当時は手で書いていた。ここでも「お前は何を言っとるんじゃ」と思うだろうが殆ど事実である。何しろ当時のFORTRAN入門書でこう書かれていたのだから事実というしかない。まずコーディングシートと呼ばれる専用の紙を用意する。ここにプログラムを書くのである。書き終わったら機械にかけると紙に書いた内容を読み取ってパンチカードに穿孔する。で、このカードを壱行ごとに機械から吐き出すのである。出力は当然この穴を開けた状態のパンチカードである。それをさらに機械に読み取らせることで、コンピューター本体のメモリにパンチカードの内容が「転送される」。そしてようやく本来の処理を始めるという訳である。
一見するとめんどくさい方法だが、こんなことをしていた理由など単純で、パンチカードの山が当時のコンピューターの外部記憶(今でいうハードディスク等である)に相当したからである。一行につき一枚のカードが使われているが書き誤りなどがあれば、そのカードを廃棄して差し替えることはできる。当時もハードディスクは存在したが、容量が低く常時ユーザーのデーターを置くなんてことは出来なかった(と思われる)。従ってこれらの高価な機材には必要な時にデーターを書き込み、使い終わったらデーターを消去するようになっていたはずである。と言うかそのようしないとデーターでHDDの容量が直ぐ一杯になるから、直ちに消せと言われまくった人もいるはずである。
これが遅くとも80年代の終わりまでの大学や企業におけるプログラムの開発状況である。もちろんFORTRANも例外ではない。
個人向けのコンピューターが出てきたのは70年代末期である。といってもCPUから始まり各素子を基盤にはんだ付けする必要があったので、電子工作の知識と実践が出来ないといけない代物だった。その後パーソナルコンピューターが販売されるに至る。今使っているパソコンの直接の起源がこれである。当時と今で異なるのは外部記憶などはなくあってもテープレコーダーを使うしか無い(ハードディスク?それって何?)事だったり、フロッピーディスクが出始めたりした時期だった。ディスプレイもブラウン管式のものしかなくテレビを使ったりしていた時代である。プログラムに使えるものといったBASICだけだった時代でもある。CやPascalが出始めたのは80年代半ばであり、実はFortranコンパイラも登場していた。嘘と思われるだろうが今のIntel FortranはMS-Fortranが起源である。
90年代になってPC用のHDDが出たが40Mbyteといったものが多かった。これでも当時としては大容量である。何事もだが当時のことを今の目では見てはいけないのである。
勿論このような外付けのソフトを動かすにはOSが必要である。8ビット機用には(私は触ったことがないが)、CP/Mというのがあった。16ビット機用には同じくCP/MやMS-DOSがあった。これらの言語製品はこの上で実行するようになっていて単独では動かなかった。今では不思議でも何でもないが、8ビット機時代のBasicが直接立ち上がって処理待ちをする時代から、明示的にOSを先に起動しそれからこれらのプログラムを実行する時代へと変わっていったのである。
プログラミングの方はどうだというと、BASICの時代には近代的プログラムの萌芽すらなかった。そりゃそうだろう。制御文はif文の他while文があったが後者が使われていたとは言い難い。どちらかというと割り当て型goto文が多用されていた。これには理由があって、外部機器を使うときの割り込みの為に使われていた。勿論計算型goto文も使われている。サブルーチンには引数なんてものはない。従って変数はこれ全て大域変数でプログラムの管理どころではない状態になる。構造体なんてのは勿論ない。
当時のgoto文の使われ方は単純なジャンプの他に割り当て型(イベントドリブン)や計算型goto文というのがあり、多重分岐にはそれらしか使えなかった。モノによってはgotoがgosubになっていたりするが同じことである。
これが当時の8ビット機における開発状況である。速度優先ならアセンブラがあったが、これも恐らく大同小異である。
それがOS上でのソフト開発が一変すると状況が変わってくる。開発には高級言語が不可欠であり、そのためにC言語が普及しだした。当時のPC上だとCの開発の主力を担っていたのはMicrosoft C Compilerである。OSベンダーの出す開発ソフト故である。これと互角の戦いを繰り広げていたのがTurbo PascalやTurbo Cを出していたBorlandだった。前者は高い最適化とベンダー提供の製品が強みだったが高価だった。対するBorlandは低価格と統合開発環境が売りだった。最も値段についてはMicrosoftだけの専売特許ではなく実は他も同じようなものである。
C言語には当時のプログラミングに必要なものが一式揃っていた。つまりこれ一つあれば現代的プログラムが組めるわけである。C言語はATTのベル研のハッカーたちがプログラマ向けに作ったのだから当然と言える。ポインタ関連が面倒くさい点を除けばだが。
こうしてC言語はプログラム言語の主流にのし上がった。これらのプログラミング言語が齎したのは高速な処理を行いうるプログラムの作成だけではない。データー構造・可読性といったソフトウエア工学の賜物である。
だがFortranはこの流れから完全に取り残された。旧規格最後のFORTRAN77の最初のコンパイラが出たのは80年代になってからである。この後の大改訂になるFortran90、最初のmodern fortranのコンパイラが出たのは93年である。ここに至ってC言語とタメを張れないことないレベルになった。
しかし猫も杓子もmodern fortranに移行とはならなかった。今問題とされているのはプログラムの可読性であり、開発効率の向上である。最早旧規格の風土病などに付き合っている暇は誰にもないのである。それもこの風土病を直そうともせずただ漫然としているだけである。要するにソフトウエア工学的見地からすれば彼らは「何もしなかった」のである。これが正しい歴史的解釈である。大学教授だのといった人種が彼らが習ったのはFORTRAN66である。80年代前半まで学生だった連中ならばこう断言しても間違いなかろう。存在しない言語処理系の教育など不可能である。
こんな連中が教鞭を取る立場になったらどうなるか。答えは明白である。要するに下手糞プログラマー(と言うのも烏滸がましい連中)が出来るだけである。更に言うと、今どきの大学は家が建つほどの授業料を取っているにもかかわらず初心者未満の連中しかできないのかという話になる。
更に問題なのは言語の機能すら熟知していない連中が量産されることである、これには根拠がある。いや、この根拠こそが問題なのだが、丸善の「Fortran90/95による有限要素法プログラミング」(藤井元岐阜大教授以下2名)のP79を見ればわかる。この部分には看過できない問題がある。要するに車輪の最発明である。
この部分の説明をすると、ファイル名に連番を入れることを考える。まぁ、hoge.001.dat、hoge.002.datという具合に最大でhoge.999.datという風にファイル名をつけるわけである。このようなファイル名をプログラム中で生成するにはどうするかである。Fortran77以降であればFORMAT文で(a,".",i3.3,".",a)を指定し、それぞれwrite文で書き込み先にファイル機番ではなく文字列を与え、引数にファイル名(この場合hoge)、番号、ファイル名を与えればよい。この部分はFORTRAN77ではこのようになる。
character(100) fname
100 format(a,".",i3.3,".",a)
write(fname,100) 'hoge',number,'dat'
書けばいいのは、たったのこれだけである。あと必要なのは桁数のチェックだけだろう。つまり書籍中にある10行以上がこれで消せることになる。それを何を考えたかだらだらと数値から文字への変換作業なるものを桁数分実行している。この方法だと桁数が多くなったときに書き直しが生じるしプログラムが無駄に長くなる。上記の方法なら3桁から4桁に増やす場合i3.3をi4.4に変更するだけである。そういえば内部ファイル機能を使う必要があるが、こんなことも知らないのが丸解りである。
modern fortranではこの部分はこうなる。
character(100):: fname
write(fname,’(a,".",i3.3,".",a)') 'hoge',number,'dat'
だがもっと重大な点がある。このような機能はANSI FORTRAN66には実はない。FORTRAN77で追加されたのである。つまり藤井以下本書の査読を行った全員がこの機能を知らなかったと言われても反論は出来ない。現実にこんな書き方しているのだからそうなる。何見てたんだというレベルではない。彼ら教授やら研究員やらはこの機能について知らなければならないはずである。使わないから知らないという言い訳も通用しない。研究員の方は兎に角、教授というのは教育者である。知らなくてどうするんだ?
この素晴らしいプログラム原文をここに書いてもいいが、いい加減指が腐るのでやめた。
更に危惧するのはどうやら日本計算工学会なるものが後援しているらしいことである。この本のカバー末尾に同会出版書籍の一覧が載せられている。このプログラムを見たはずの一人、生出佳もここの会員である。なんでも調布の方のメカニカルデザインの研究者とあるが、ここの研究員ですらこれでは絶望しかないのが解っているのだろうか。豊田中研の連中諸共解かってはおるまいな。それとも藤井が駄々でも捏ねまくったのだろうか。共著者と査読者全員の顔に泥どころか糞尿を塗りたくる行為にしかならないのだが。
これには後日談がある。勤め先でも同じようなものを見たのである。こちらは書式設定にi0を用いて数値を文字列化し、行頭に0を追加するという方法をとっているが、面倒は同じである。最大桁数が固定ならば上の方法をとったほうが余程スマートである。それは兎に角、これを書いた研究員が岐阜大出身とは思えないから、話を際限なく大きくするとこのような知っておいても損しない機能についてはどこも教えていないということになる。
ここまでくると、今まで何を教えていたんだと言いたいが、教育の目的として置くべきはセミプロ並みのプログラムを書けるようにするべきである。金をふんだくって出来上がるのが3流未満は許されないのである。この調子で(退役したが)京や富岳を使わせる気かといいたくなる。効率の悪い書き方をするのが目に見えているので、コンパイラは一杯仕事するしかなく、最新のアーキテクチャーに関係ないコードを生成するのだけは分かる。
この書籍のプログラムに横溢しているのは結果としての開発効率の軽視である。後の方に出てくる要素剛性行列の計算部分を見ればわかると思うが、何かの修行かといいたくなる内容である。同じ問題が日刊工業新聞社の「有限要素法のつくり方!」にもある。この本の内容も大概で京大の副学長様が前書きを書いているが騙されてはいけない。これらの本は一言で言って有害図書である。この書籍の内容はその偉い人の顔に泥を塗りたくる作業である。それともこいつら全員特殊な趣味でもあるんですかね?ああ、自分の顔じゃないからいいのか。そうなのか。
問題その2は初心者向けに書いた気になっているころだろう。それすら怪しいのだが。第一初心者を初心者のままにしてどうする。初心者は初心者から脱出できない内容である。この調子で教えていたらそりゃ世界で通用するソフトウエアの作成など只の妄想である。だって設計すら教えないんだもの。できるわけがない。
と思ったら、下には下がいた。いて欲しくなかったんですが。東大の中島研吾教授の熱伝導解析プログラムである。まず冒頭に燦然と輝くimplicit real*8が存在する。不適切な命名ばかりが並ぶ変数表を見ると暗然たる気持ちになる。何で節点総数が二つあるのか意味不明であるし、その名前もよりによってNとNPである。一文字の大域変数など悪夢の始まりそのものである。特にNのような変数はループで使われやすい。こんなもんを出した時点で、またデーターモジュール名が全く意味をなさないpfem_utilである時点でどうしようもない。
つまり変数名の付け方が不適切である。例えば最大反復回数にはITERが使われているが、MXITERにでもしたらよかっただろう。ただのITERにはそんな意味はない。このほかにITER_ACTUALとかという変数があってこれが只の反復回数である。ならばそれぞれ単純にMAX_ITER・ITERにすればよい。他ではこうしているのに、なんでこんな命名をしているのか理解できない。この世界では長いものに巻かれたり寄らば大樹の陰は大正義だったりする。この長いものや大樹は世間一般では標準というが、それに従っておけば問題ないという意味である。他にも節点セットを配列化しているが、構造体にするべきである。MPP版ではそうしているのに何故やらない。これも名前の配列、セット当たりの節点の個数をそれぞれ配列にしているが、なら肝心の節点リストはどうなっているかというと、全部一つの配列に押し込んでいる。こんな手間暇かけるくらいなら構造体にして番号・名前・節点数・節点リストをひとまとめにするのがよい。というか。そうしろやと怒鳴りつけたくなる。よくこんなものをYouTubeに出したと感心するが(中島以下関係者全員にとっては)どこも違和感がないのだろう。
また、読み込んだ変数をプログラム中で破壊している。これもコネクティビティであれば、読み込んだ節点番号と実際のデーターの位置が異なることは日常茶飯事なので内部インデックスに置き換える必要があるから仕方ないともいえるが、このプログラムでは反復計算における許容値を破壊している。混乱の元である。この変数はRESIUという名前だがこれも適切ではない。共益勾配法の許容値なんだから、CG_TOLとした方がよかっただろう。RESIUの元になったresiualという単語はどちらかというと残りの意味であって自分の知る限り許容値の意味ではない。それはtoleranceである。構造解析ではこのようになるが熱伝導解析では異なるので主か?それとも英語も残念なんですか?
慣用的に使われる単語を慣用的に使わないのに何か意味があるのだろうか。
因みにresidualには「説明のつかない」「除去できない」の意味もある。普通は「残りの」「残余の」という意味で使われている。いずれにしても許容値という意味で使うのは間違っているとしか言いようがない。
で、なんでこんなことしなきゃならんのだ
構造解析における要素剛性行列の計算に相当する要素熱容量行列の計算を行っているJACOBという副プログラムだが、パラメーターが31個も並んでいる。藤井もだが、抑々こんなにだらだらと並べたらサブルーチンを呼び出すのに時間がかかるだろうが。この連中は今の関数呼び出しのシーケンスも知らないと見える。
まず関数を呼び出すにあたってこれらのパラメーターはスタックに積まれる。Intelベースのアーキテクチャーだと最初の4個がレジスタ行になる。勿論レジスタ内のデーターを上書きするので、これらもスタックに退避する必要が生じるが、こうすることで、実行時の負担を低くしているのである。中島の場合、31個のうち24個が座標データーなので一つの配列にまとめることが出来る。これで8個にまで減った。藤井の場合引数は10個あるが8個がコネクティビティだから、これも配列にすれば全部スタックではなく、レジスタに格納されることになり、ただのジャンプ命令同然となる。更に最初の2個はヤング率とポアソン比だから、これも初めからDマトリックスにしておけばパラメータは僅か2個にまで減少するし、例題中にあるように要素ごとにDマトリックスを計算する手間を省ける。要するに設計の不備である。
中島の場合最初の一つがヤコビアンの行列式、次の3個が∂N/∂X・∂N/∂Y・∂N/∂Zでさらに∂N/∂r1・∂N/∂r2・∂N/∂r3が続く。これらを纏めると最終的に引数は4個となり全部レジスタに格納できる。
どうしてこんな書き方をするのかというと、こちらが早いと考えているんだろう。実際70年代のコンピューターであれば早い方法だった。コンピューターにはスタックなんてものがないことがザラである、嘘と思うだろうがIBMのマシンにはそんなものが無かったことが知られる。次にFortranの副プログラムの引数は変数のアドレスを渡している。つまり値をコピーするのではなく、変数の在処を副プログラムに教えているわけだ。だから呼び出した先で引数の値をうっかり変更しようものなら、意味不明なエラーが生じることになる。それは置くとして、では、これらの副プログラムを一度しか呼ばない場合はどうなるかである。そのような場合、引数のアドレスを呼び出し先のアドレスに置き換えればいい。そうすれば処理はジャンプ分を挟むにしてもシームレスなものとなるし、実行速度も上がることが期待できる。
そして藤井諸共X1からX8のようにだらだらと変数を個別に宣言しているのも同じ理由である。スタックなぞ無いから変数はこれ全て大域領域に置かれることになる。通常コンパイラは出てきた順に変数をメモリ上に配置するだろうから、それを期待した最適化も行いうる。そんなところだろう。であればこれらの変数を用いた内積の計算もいちいち手で展開しているのも説明がつく。ループを使えばいいのにと思うし、今のFortranならdot_productがある。これを使えば、ループを使わずに済むし、コンパイラによってはもっといいコードを生成する可能性だってある。
しかし、ループを使えばその分処理時間がかかるから手で展開したほうが早い、そういうことなのだろう。何しろ昔はコンピューターそのものの処理が遅かったのである。処理速度を稼ぐにはループを使わなければいいということになる。
しかし、今は違う。コンピューターの処理速度は大幅に上がった。処理速度は機械によるが桁違いなはずである。それよりもソフトウエアの大規模化や複雑化に伴て可読性やコード開発の効率化が重視されるようになった。それらを無視しているのは計算力学だけではないのか。
そして、なぜ一体であるべき変数をばらすと駄目なのかを説明すると、これらはスタックに積まれることになる。そうであれば、これらは全部スタックポインタ相対でアクセスされる。期待が持てるとしたら変数によっては連続した領域に配置されるだろうから、それを基にした最適化を行ってくれるという希望である。だが、そういう風にはならない。配列であればどこにあっても連続した領域に配置されるという仮定を置くことが出来るから、ベクトル化といった最適化を容易に行いうる。だが個別の変数とした場合、コンパイラがその仮定はしないとしても文句は言えない。しなかったらどうなるかというと昔懐かしい書き方をしたコードが吐き出されることになる。嘘だと思うんなら一度アセンブラ出力をしてみることを薦める。本当にそうなるのだ。
更に今のCPUのレジスタは64ビットとは限らない。モノによってはこの8倍の512ビットなんてのもある。倍精度実数なら8個のデーターを格納できるサイズである。この二人の書いたプログラムで使われている要素は6面体一次要素といい、節点数は8個である。つまり各データーが8個ある。SIMD計算をフルに使えた場合、ヤコビアンの計算では、格納6回、並列乗算9回、水平加算9回、ストア9回で済むが、昔懐かしい方法では一つの要素の計算で格納16回、乗算8回、加算7回、ストア1回である。格納については工夫すれば48回に収まるがレジスタも48個必要である。因みにIntel CPUのレジスタは16か32個の筈だから全然不足である。さらに工夫してもストア32回だが、これだけでレジスタを使い切ることになる。
その中島が教えているのがHPCである。なんでもHigh Performance Computingの略らしいが、このプログラムを見る限りそんなものはどこにも見えない。
ついでに下らない部分があったので指摘しておく。このプログラムでは全体剛性の計算に先にも書いたように共益勾配法が使われており、全体剛性行列を作る際に0でない部分だけを記憶するようにしている。この中で各行の処理を行う際に、必要な部分だけ記憶するという作業がある。この位置を記憶するのに際して、何を思ったか大きい順に並べ直し、格納時には小さい順に並べ直す(要するに逆順に代入)しているのである。こんなことをするくらいなら初めから専用のルーチンを作成し、データーに各行の情報を渡せば一発である。どこがハイパフォーマンス何だろうか。
このほかにも56回のおんなじサブルーチンの呼び出しがあったりする。これも渡される変数名を見ると要素内部の節点番号を配列ではなくばらしたものを渡している。同じものを渡す場合は処理しないようにしているが、そんなものはサブルーチン内で直ちに帰るようにすればそんな面倒なことはしなくて済む。引数も配列にしておけば二重ループを書くだけで済む。突っ込みどころ満載である。
で、中島研吾のプロフィールを見たら日本計算工学会会員とあった。藤井の本といい、こいつの本といい、ここは下手糞なプログラムを曝す趣味でもあるんだろうか。
要するに昔々学生の頃習った方法に固執しているだけの輩が教授になると、こうなるということである。そこには他言語で取り入れられている流儀やいい点を取るということはしない。その結果古臭い方法が目立つものとなり、この結果がFortran撲滅論に繋がるわけである。
Fortran撲滅論を潰すいい方法は一つしかない。それは現在使われている主要言語と遜色のない書法を使うことであり、プログラムやデーターの設計といったものに気を配ることである。この部分が今@本的に欠如しているのが問題なのだが。それにもかかわらず最新のソフトウエア作成論に従ったものを書いて、今のFortranが「古くて新しい」ものであることを証明するしかないだろう。